File-System Layout

File
Systems are stored on disks. The above figure depicts a possible File-System
Layout.
- MBR: Master
Boot Record is used to boot the computer
- Partition
Table: Partition
table is present at the end of MBR. This table gives the starting and
ending addresses of each partition.
- Boot
Block: When
the computer is booted, the BIOS reads in and executes the MBR. The first
thing the MBR program does is locate the active partition, read in its
first block, which is called the boot block, and execute it. The program
in the boot block loads the operating system contained in that partition.
Every partition contains a boot block at the beginning though it does not
contain a bootable operating system.
- Super
Block: It
contains all the key parameters about the file system and is read into
memory when the computer is booted or the file system is first touched.
Implementing
Files
Contiguous
Allocation: Each file is stored as a contiguous
run of disk blocks. Example: On a disk
with 1KB blocks, a 50KB file would be allocated 50 consecutive blocks. With 2KB
blocks it would be 25 consecutive blocks.
Advantages:
Simple to implement.
The read performance
is excellent because the entire file can be read from the disk in a single
operation.
Drawbacks:
Over the course of
time the disk becomes fragmented.
Linked
List Allocation:
The second method for
storing files is to keep each one as a linked list of disk blocks. The first
word of each block is used as a pointer to the next one. The rest of the block
is for data. Unlike Contiguous allocation no space is lost in disk fragmentation.
Layered File System

I/O control:: device drivers and
interrupt service routines that
perform the actual block transfers.
Basic file system:: issues generic
low-level commands to
device drivers.
File organization:: translates logical
block addresses to physical
block addresses.
Logical-file-system::Handles metadata that includes filesystem structure (e.g., directory structure and file control blocks (FCB’s)
Virtual
File Systems:
An operating system
can have multiple file systems in it. Virtual File Systems are used to
integrate multiple file systems into an orderly structure. The key idea is to
abstract out that part of the file system that is common to all file systems
and put that code in a separate layer that calls the underlying concrete file
system to actually manage the data.
Structure of Virtual
File Systems in UNIX system:

The VFS also has a
'lower' interface to the concrete file systems, which is labeled VFS interface.
This interface consists of several dozen function calls that the VFS can make
to each file system to get work done. VFS has two distinct interfaces: the
upper one to the user processes and the lower one to the concrete file systems
VFS supports remote file systems using the NFS (Network File System) protocol.
File Access Methods
Let's look at various ways to access files stored in secondary memory.
- Sequential Access:
- Direct Access:
- Indexed Access:
1.Sequential Access:
Most of the operating systems access the file sequentially. In other words, we can say that most of the files need to be accessed sequentially by the operating system.In sequential access, the OS read the file word by word. A pointer is maintained which initially points to the base address of the file. If the user wants to read first word of the file then the pointer provides that word to the user and increases its value by 1 word. This process continues till the end of the file, due to the fact that most of the files such as text files, audio files, video files, etc need to be sequentially accessed

2.Direct Access:
The Direct Access is mostly required in the case of database systems. In most of the cases, we need filtered information from the database. The sequential access can be very slow and inefficient in such cases.Suppose every block of the storage stores 4 records and we know that the record we needed is stored in 10th block. In that case, the sequential access will not be implemented because it will traverse all the blocks in order to access the needed record.
Direct access will give the required result despite of the fact that the operating system has to perform some complex tasks such as determining the desired block number. However, that is generally implemented in database applications.

3.Indexed Access:
If a file can be sorted on any of the filed then an index can be assigned to a group of certain records. However, A particular record can be accessed by its index. The index is nothing but the address of a record in the file.
In index accessing, searching in a large database became very quick and easy but we need to have some extra space in the memory to store the index value.

Directory
Directory can be defined as the listing of the related files on the disk. The directory may store some or the entire file attributes.To get the benefit of different file systems on the different operating systems, A hard disk can be divided into the number of partitions of different sizes. The partitions are also called volumes or mini disks. Each partition must have at least one directory in which, all the files of the partition can be listed. A directory entry is maintained for each file in the directory which stores all the information related to that file.
A directory can be viewed as a file which contains the Meta data of the bunch of files.Every Directory supports a number of common operations on the file:
1. File Creation
2. Search for the file
3. File deletion
4. Renaming the file
5. Traversing Files
6. Listing of files
Single Level Directory
The simplest method is to have one big list of all the files on the disk. The entire system will contain only one directory which is supposed to mention all the files present in the file system. The directory contains one entry per each file present on the file system.

This type of directories can be used for a simple system.
Advantages
1. Implementation is very simple.
2. If the sizes of the files are very small then the searching becomes faster.
3. File creation, searching, deletion is very simple since we have only one directory.
Disadvantages
1. We cannot have two files with the same name.
2. The directory may be very big therefore searching for a file may take so much time.
3. Protection cannot be implemented for multiple users.
4. There are no ways to group same kind of files.
5. Choosing the unique name for every file is a bit complex and limits the number of files in the system because most of the Operating System limits the number of characters used to construct the file name.
Two Level Directory
In two level directory systems, we can create a separate directory for each user. There is one master directory which contains separate directories dedicated to each user. For each user, there is a different directory present at the second level, containing group of user's file. The system doesn't let a user to enter in the other user's directory without permission.
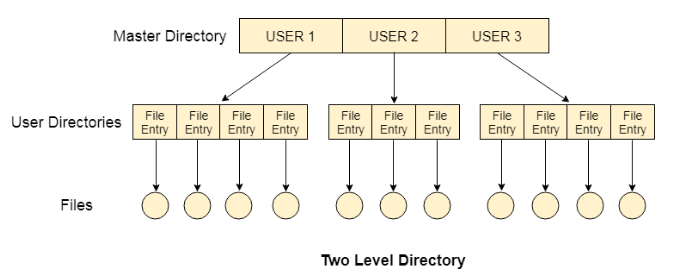
Characteristics of two level directory system
1. Each files has a path name as /User-name/directory-name/
2. Different users can have the same file name.
3. Searching becomes more efficient as only one user's list needs to be traversed.
4. The same kind of files cannot be grouped into a single directory for a particular user.
Every Operating System maintains a variable as PWD which contains the present directory name (present user name) so that the searching can be done appropriately.
Tree Structured Directory
In Tree structured directory system, any directory entry can either be a file or sub directory. Tree structured directory system overcomes the drawbacks of two level directory system. The similar kind of files can now be grouped in one directory.

Each user has its own directory and it cannot enter in the other user's directory. However, the user has the permission to read the root's data but he cannot write or modify this. Only administrator of the system has the complete access of root directory.
Searching is more efficient in this directory structure. The concept of current working directory is used. A file can be accessed by two types of path, either relative or absolute.Absolute path is the path of the file with respect to the root directory of the system while relative path is the path with respect to the current working directory of the system. In tree structured directory systems, the user is given the privilege to create the files as well as directories
Permissions on the file and directory
A tree structured directory system may consist of various levels therefore there is a set of permissions assigned to each file and directory.
The permissions are R W X which are regarding reading, writing and the execution of the files or directory. The permissions are assigned to three types of users: owner, group and others.
There is a identification bit which differentiate between directory and file. For a directory, it is d and for a file, it is dot (.)
The following snapshot shows the permissions assigned to a file in a Linux based system. Initial bit d represents that it is a directory.

Acyclic-Graph Structured Directories
The tree structured directory system doesn't allow the same file to exist in multiple directories therefore sharing is major concern in tree structured directory system. We can provide sharing by making the directory an acyclic graph. In this system, two or more directory entry can point to the same file or sub directory. That file or sub directory is shared between the two directory entries.

These kinds of directory graphs can be made using links or aliases. We can have multiple paths for a same file. Links can either be symbolic (logical) or hard link (physical).
If a file gets deleted in acyclic graph structured directory system, then
1. In the case of soft link, the file just gets deleted and we are left with a dangling pointer.
2. In the case of hard link, the actual file will be deleted only if all the references to it gets deleted.
Allocation Methods
There are various methods which can be used to allocate disk space to the files. Allocation method provides a way in which the disk will be utilized and the files will be accessed.
1. Contiguous Allocation.
2. Linked Allocation
3. FAT

Contiguous Allocation
If the blocks are allocated to the file in such a way that all the logical blocks of the file get the contiguous physical block in the hard disk then such allocation scheme is known as contiguous allocation.
In the image shown below, there are three files in the directory. The starting block and the length of each file are mentioned in the table. We can check in the table that the contiguous blocks are assigned to each file as per its need.

Advantages
1. It is simple to implement.
2. We will get Excellent read performance.
3. Supports Random Access into files.
Disadvantages
1. The disk will become fragmented.
2. It may be difficult to have a file grow.
Linked List Allocation
Linked List allocation solves all problems of contiguous allocation. In linked list allocation, each file is considered as the linked list of disk blocks. However, the disks blocks allocated to a particular file need not to be contiguous on the disk. Each disk block allocated to a file contains a pointer which points to the next disk block allocated to the same file.

Advantages
1. There is no external fragmentation with linked allocation.
2. Any free block can be utilized in order to satisfy the file block requests.
3. File can continue to grow as long as the free blocks are available.
4. Directory entry will only contain the starting block address.
Disadvantages
1. Random Access is not provided.
2. Pointers require some space in the disk blocks.
3. Any of the pointers in the linked list must not be broken otherwise the file will get corrupted.
4. Need to traverse each block.
File Allocation Table
The main disadvantage of linked list allocation is that the Random access to a particular block is not provided. In order to access a block, we need to access all its previous blocks.
File Allocation Table overcomes this drawback of linked list allocation. In this scheme, a file allocation table is maintained, which gathers all the disk block links. The table has one entry for each disk block and is indexed by block number.
File allocation table needs to be cached in order to reduce the number of head seeks. Now the head doesn't need to traverse all the disk blocks in order to access one successive block.
It simply accesses the file allocation table, read the desired block entry from there and access that block. This is the way by which the random access is accomplished by using FAT. It is used by MS-DOS and pre-NT Windows versions.

Advantages
1. Uses the whole disk block for data.
2. A bad disk block doesn't cause all successive blocks lost.
3. Random access is provided although its not too fast.
4. Only FAT needs to be traversed in each file operation.
Disadvantages
1. Each Disk block needs a FAT entry.
2. FAT size may be very big depending upon the number of FAT entries.
3. Number of FAT entries can be reduced by increasing the block size but it will also increase Internal Fragmentation.











